
Une bonne circulation de l’air est essentielle pour éviter que la condensation et l’humidité ne s’accumulent sous la housse. Recherchez des variantes dotées d’aérations intégrées

Le choix d’une bonne paire de gants de motocyclisme ne se limite pas à une simple question de protection. Vos gants sont votre principal point

Les gens confondent parfois les enzymes et les probiotiques. Les deux agissent sur la digestion, mais de manière très différente. Les probiotiques sont des organismes

Au cœur de la perle verte de l’Europe, la République de Slovénie, il existe un paradis souterrain fascinant : la grotte de Postojna. L’époustouflant système
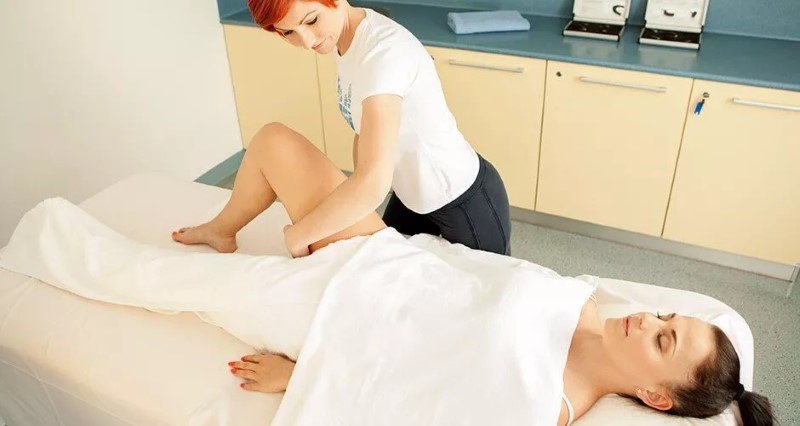
La thérapie Bowen de Thermana Laško est l’un des services préférés des clients pour de nombreuses bonnes raisons. Thermana Laško dispose d’une équipe spéciale d’ergothérapeutes

Avez-vous déjà fait l’expérience de transporter un matelas double sur le toit de votre voiture, avec une de vos mains qui s’étend vers l’extérieur pour

l est extrêmement important que vous connaissiez les principales différences entre une sangle de récupération et une sangle de remorquage que vous pouvez acheter dans

Le moringa est une plante originaire des régions de l’Inde, du Pakistan, du Bangladesh et de l’Afghanistan, mais il est également cultivé sous les tropiques.

Si un site Web demande aux utilisateurs de se connecter, de saisir des données personnelles telles que des numéros de carte de crédit ou de

C’est une question difficile qui dépend du temps et du budget que vous investirez dans votre balcon ou votre jardin et si le vase que
View More